本文系统梳理 LangChain 核心组件的使用方法与工作原理,按照 Agent 的工作流程划分为 Prompt Engineering、Memory、Tools、RAG 四个核心模块。
一、概述
1.1 什么是 LangChain
- LangChain 的定位与核心价值
LangChain 是一个帮助你构建 LLM 应用的 全套工具集 。涉及到prompt 构建、LLM 接入、记忆管理、工具调用、RAG、智能体开发等模块。 - RAG架构开发
RAG(Retrieval-Augmented Generation),检索增强生成,目的是减少大模型的幻觉,提升回答质量,其流程如图。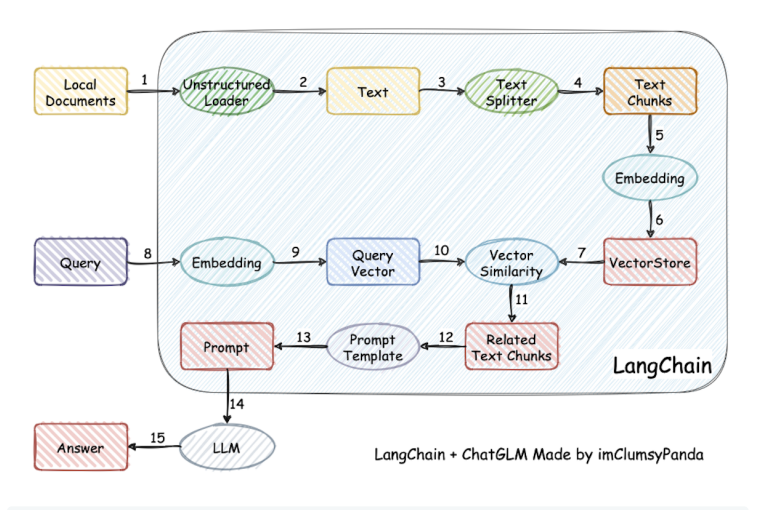
用户提问后,模型会从本地的向量数据库去寻找向量方向相近的内容,然后将内容与用户的问题结合提示词一起交给大模型去生成结果。 - Agent架构开发
如果只能给出文本,或者说对话的话,终究只是纸上谈兵的llm,而agent就是给其工具,让其能通过工具去完成任务(要区别于强化学习的agent)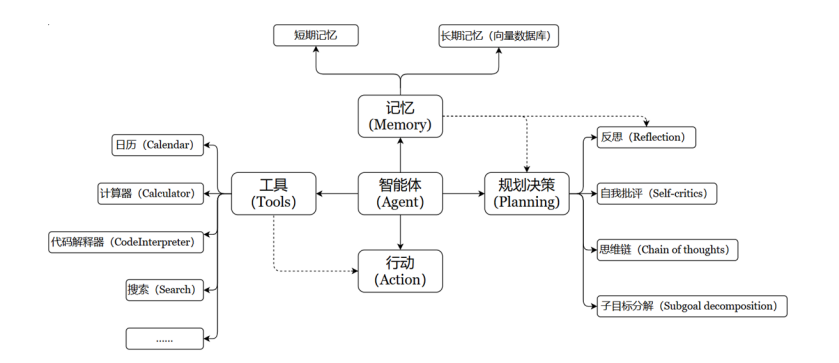
1.2 LangChain的安装
推荐使用PyCharm编译器,建议下载专业版,专业版可以远程连接云服务器;如果是新了解python学习的,建议先了解一下Anaconda创建py隔离环境,避免py环境之间的污染
1 | pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple |
1.3 LangChain的框架
1 | #获取api和url的变量 |
二、Model I/O
2.1 调用模型
模型可以分为非对话模型,对话模型,嵌入模型。调用模型之前要要在环境变量或者配置文件配好申请到的大模型api和url
1 | #LangChain的“hello world”,以qwen模型为例 |
ChatOpenAI的必须参数为base_url,api_key,model,其他参数也有:temperature:控制文本的“随机性”,取值范围为0-1,越高越“抽象”,越低越“保守”max_tokens:限制文本生成的最大token数,不过qwen的调用好像不是这个参数
不同的模型调用请参考各官方的操作手册invoke()方法为阻塞式输出,会一次性生成ai回答结果,如果想向ds等模型那样一点一点的生成结果,可以在模型中设置streaming = True或者使用stream()调用,对于多个HumanMessage的请求,可以使用batch()进行批量调用
2.2 message的类型
SystemMessage 为AI的行为规则或背景信息,比如“你是智能助手科塔娜”HumanMessage 表示来自用户的输入AIMessage 一般存储AI回复的内容
1 | messages = [ |
这里可以看到SystemMessage有点类似于提示词的功能
2.3 PromptTemplate
1 | from langchain_core.prompts import PromptTemplate |
2.4 ChatPromptTemplate
相比于PromptTemplate,ChatPromptTemplate是创建聊天消息列表的提示词模板,更适合处理多角色,多轮次的对话场景
1 | from langchain_core.prompts import ChatPromptTemplate |
2.4 输出解析器
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的 输出解析器 就派上用场了。
LangChain有许多不同类型的输出解析器:StrOutputParser :字符串解析器JsonOutputParser :JSON解析器,确保输出符合特定JSON对象格式XMLOutputParser :XML解析器,允许以流行的XML格式从LLM获取结果CommaSeparatedListOutputParser :CSV解析器,模型的输出以逗号分隔,以列表形式返回输出DatetimeOutputParser :日期时间解析器,可用于将 LLM 输出解析为日期时间格式OutputFixingParser :输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合预期格式的输出,尝试修正为正确的结构化数据(如 JSON)
1 | ##使用StrOutputParser() |
三、Memory(记忆系统)
3.1 Memory 的核心概念
- 为什么需要 Memory
正常调用大模型是不会记住上下文的,也就是上一次调用大模型的对话内容下一次调用大模型时,大模型是不会“记得”的。
3.2 底层存储类ChatMessageHistory
作为所有记忆组件的底层基础,仅负责纯消息对象的存储 / 管理(直接操作HumanMessage/AIMessage等对象),无任何记忆策略(无裁剪、无摘要、无筛选),也不涉及消息格式化(如转字符串)
3.3 基础记忆类
- ConversationBufferMemory
按原始顺序完整存储所有对话历史,无裁剪、无压缩,是最基础的对话记忆组件;可通过memory_key自定义历史变量名,return_messages控制输出格式
1 | #先要调用大模型,这里省略调用大模型的代码了 |
- ConversationBufferWindowMemory
在ConversationBufferMemory基础上增加窗口限制,仅保留最近 k 条对话交互,按对话条数裁剪历史,避免内存 /token 过载。超出k条的对话内容则直接丢失,会错失早期信息。
3.4 进阶记忆类
ConversationBufferWindowMemory
基于Token 数量精准控制记忆容量,设置max_token_limit阈值,超阈值时自动移除最早的消息,保留原始对话内容(无压缩 / 摘要)ConversationSummaryMemory
通过大模型自动生成对话摘要,用精简的摘要文本替代原始对话存储,新对话加入时会动态更新摘要(旧摘要 + 新对话→新摘要),大幅压缩历史内容。
1 | from langchain_classic.memory import ConversationSummaryMemory |
-ConversationSummaryBufferMemory
融合ConversationBufferMemory和ConversationSummaryMemory, 保留最近 N 条原始对话,对超出缓冲区的早期对话生成摘要,平衡最新交互的细节和早期对话的核心信息。
1 | from langchain_classic.memory.summary_buffer import ConversationSummaryBufferMemory |
四、Tools(工具调用)
4.1 Tool 基础定义
Tools 用于扩展大语言模型(LLM)的能力,使其能够与外部系统、API 或自定义函数交互,从而完成仅靠文本生成无法实现的任务(如搜索、计算、数据库查询等)。Tools 本质上是封装了特定功能的可调用模块,是Agent、Chain或LLM可以用来与世界互动的接口。
@tool装饰器
用装饰器快速封装函数为工具,默认用函数名做工具名、文档字符串做描述
1 | #使用@tools定义工具 |
StructuredTool
类方法创建工具,配置项更丰富,支持同步 / 异步实现
1 | #StructuredTool的from_fuction()的使用 |
4.2 工具调用示例
1 | import json |
五、RAG(检索增强生成)
5.1 RAG
RAG(检索增强生成)是缓解 LLM 幻觉、接入私有 / 实时知识的核心方案,LangChain Retrieval 模块封装了 RAG 全流程,用于构建私有知识库问答。
- 文档加载器
- 文档拆分器
- 嵌入模型
- 向量存储
- 检索器
六、Agent 系统
6.1 Agent 核心概念
- Agent = LLM + Tools + Memory + Planning
LLM是大预言模型,也仅仅是语言模型,他做不了事情。但agent,他具有大语言模型做决策推断,配备有记忆能够上下文联系,也能调用工具完成任务,也被称之为智能体。 - ReAct 推理模式
原理:思考→行动→观察循环,用自然语言做推理
这里的案例中,给了模型两个工具,但模型自行推理判断只需要使用Search工具即可。
1 | import os |
七、Chains(链式组合)
7.1 基础 Chain 类型
Chain:链,用于将多个组件(提示模板、LLM模型、记忆、工具等)连接起来,形成可复用的 工作流 ,完成复杂的任务。Chain 的核心思想是通过组合不同的模块化单元,实现比单一组件更强大的功能。
LLMChain- 基础链
这个链至少包括一个提示词模板(PromptTemplate),一个语言模型(LLM 或聊天模型)。SimpleSequentialChain- 顺序链
最简单的顺序链,多个链 串联执行 ,每个步骤都有 单一 的输入和输出,一个步骤的输出就是下一个步骤的输入,无需手动映射。SequentialChain- 多输入输出链RouterChain- 路由链
7.2 LCEL (LangChain Expression Language)
|管道操作符Runnable接口- 链式组合最佳实践
- 并行执行与批处理
7.3 复杂工作流构建
- 条件分支
- 循环与递归
- 错误恢复机制
八、高级主题
8.1 回调与监控
- Callbacks 系统
- LangSmith 集成
- 日志与追踪
8.2 配置与部署
- 环境变量管理
- 模型切换策略
- 生产环境注意事项
8.3 性能优化
- 批处理 (Batching)
- 缓存策略
- 异步调用
九、实践案例
9.1 案例一:智能客服机器人
- 需求分析
- 架构设计
- 完整代码实现
9.2 案例二:知识库问答系统
- RAG Pipeline 搭建
- 多轮对话支持
- 效果评估与迭代
9.3 案例三:Multi-Agent 协作系统
- Agent 角色定义
- 任务分配与协作
- 结果汇总
十、资源
10.1 参考资源
- 官方文档
- GitHub 示例
- 社区生态(LangGraph、LangServe 等)
附录
本文持续更新中,如有错误或补充欢迎指正。
